|
I am a member of technical staff at x.ai, working on video models. Before that, I completed my PhD at BAIR, UC Berkeley advised by Prof. Jitendra Malik. I was also visiting researcher at Meta AI working with Dr. Christoph Feichtenhofer during my PhD. At Berkeley, I worked on video models, specifically focusing on human reconstruction, tracking and recognition. I also worked on exploring scaling behaviours of video generative models in terms of compute, data and inference for understanding the world from videos. Before coming to Berkeley, I was working with Prof. Salman Khan at Inception Institute of AI. I completed my undergraduate study at University of Moratuwa, with a major in Electronic and Telecommunication Engineering. My Bachelor's Thesis was advised by Dr. Ranga Rodigo. |

|
|
I recently started turning some random ideas into blog posts. The ideas are mine, and I used LLMs to help materialize them into writing. I have not spent too much time polishing them, so please read them with a grain of salt.
What Thiruvalluvar Knew About Intelligence
May 2026
A classical Tamil definition for seeing past surfaces in a noisy world.
From Fermat to Flow Matching
May 2026
A three-hundred-year path from least action to modern generative models. |
|
My research interests lie in the general area of computer vision and deep learning, particularly in learning from videos, deep neural architectures and continual learning. |

|
xAI project page/ blog/ demo Grok Imagine is xAI's multimodal generation system that creates photoreal images and short videos with native audio from text prompts. I worked on pretraining and lead distillation efforts for v0.9 and developed new post training algorithms for v1 and above. |
|
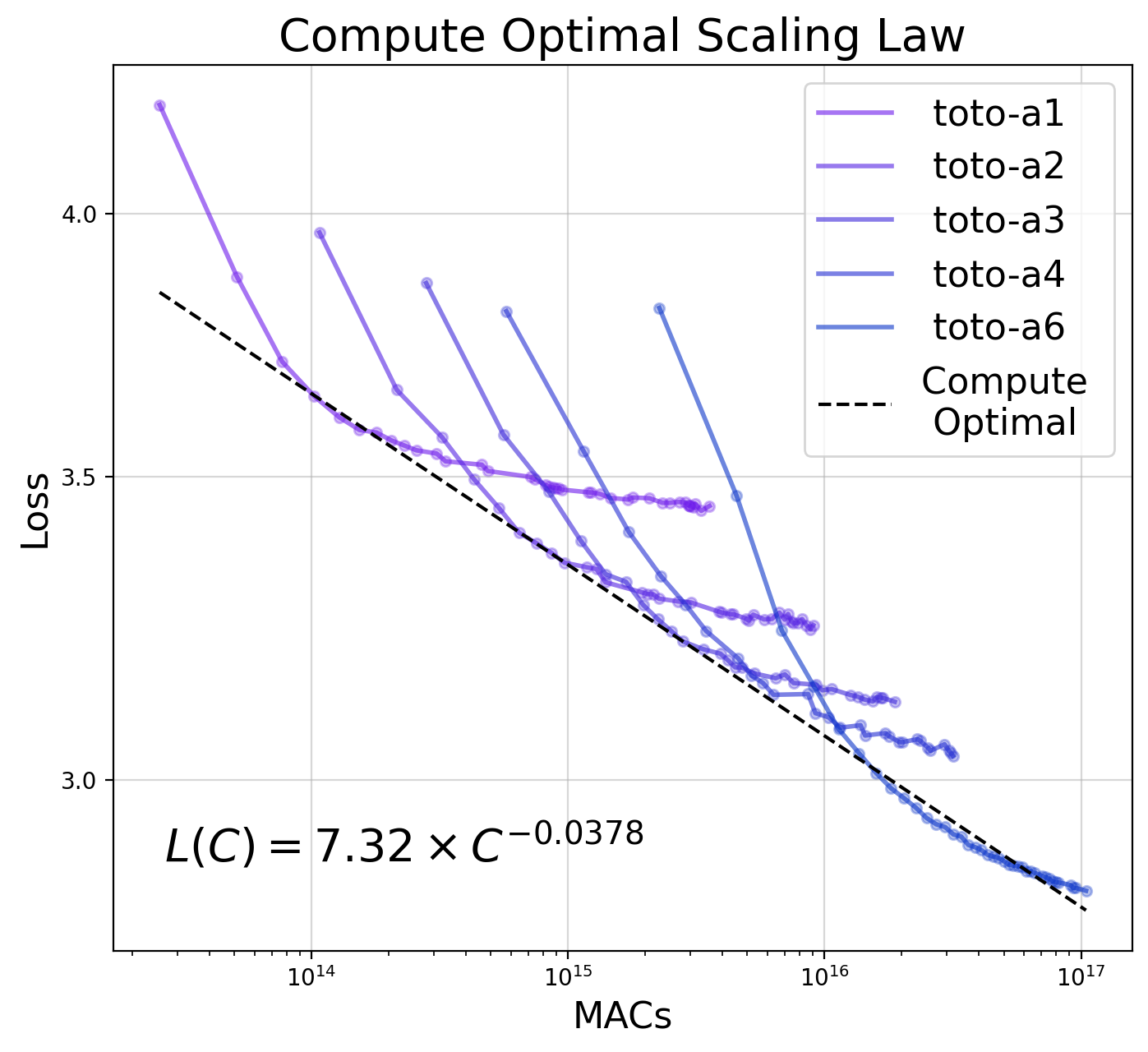
Jathushan Rajasegaran, Ilija Radosavovic, Rahul Ravishankar, Yossi Gandelsman, Christoph Feichtenhofer, Jitendra Malik International Conference on Computer Vision (ICCV) , 2025 project page/ arxiv/ code We trained LLaMA models up to 1 billion parameters on 1 trillion visual tokens. The resulting model can do diverse tasks from image, video recognition, video tracking, action prediction, and robotics. We also study the scaling properties of these family of models. |

|
Jathushan Rajasegaran, Xinlei Chen, Rulilong Li, Christoph Feichtenhofer, Jitendra Malik, Shiry Ginosar project page/ arxiv/ We trained a masked autoencoder with 3D Gaussians as intermediate representations. This allows the models to do zero-shot figure-ground segmentation, image layering, edge detection, while performing same as supervised finetuning tasks. |

|
Rahul Ravishankar*, Zeeshan Patel*, Jathushan Rajasegaran, Jitendra Malik Computer Vision and Pattern Recognition (CVPR) , 2025 project page/ arxiv/ Code We show how diffusion models benefit from scaling training and test-time compute for perceptual tasks and unify tasks such as depth estimation, optical flow, and amodal segmentation under the framework of image-to-image translation. |

|
Ilija Radosavovic, Bike Zhang, Baifeng Shi, Jathushan Rajasegaran, Sarthak Kamat, Trevor Darrell, Koushil Sreenath, Jitendra Malik Conference on Neural Information Processing Systems (NeurIPS) , 2024 project page/ arxiv Real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. |
|
|
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, Jitendra Malik International Conference on Computer Vision (ICCV) , 2023 project page/ arxiv/ code/ demo A fully "transformerized" design for Human Mesh Recovery achieves improved precision and remarkable robustness for 3D human reconstruction and tracking. |
|
|
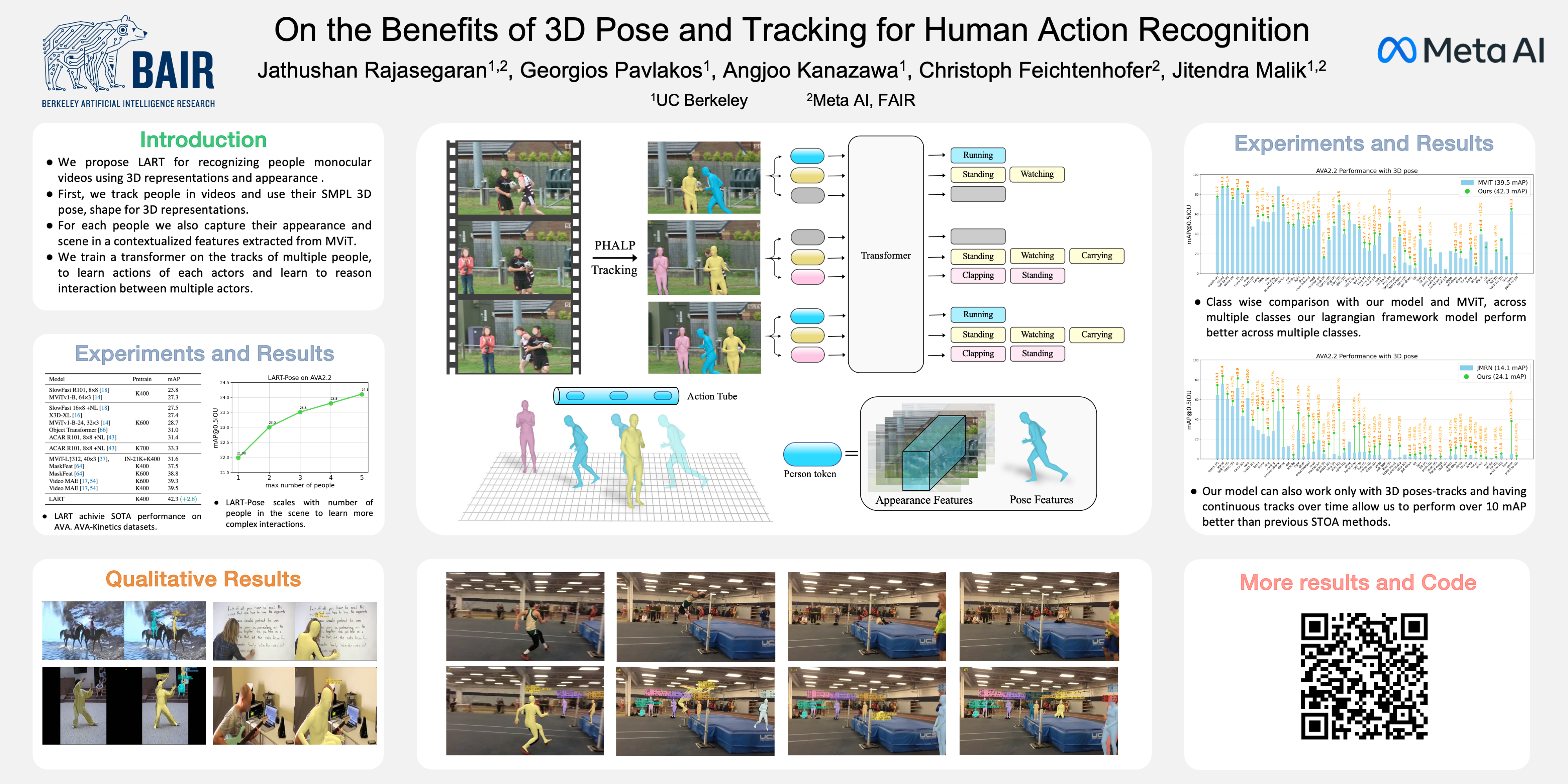
Jathushan Rajasegaran, Georgios Pavlakos, Angjoo Kanazawa, Christoph Feichtenhofer, Jitendra Malik Computer Vision and Pattern Recognition (CVPR) , 2023 project page/ paper/ arxiv/ code/ demo/ poster Using 3D human reconstruction and tracking to recognize atomic actions in video. |
 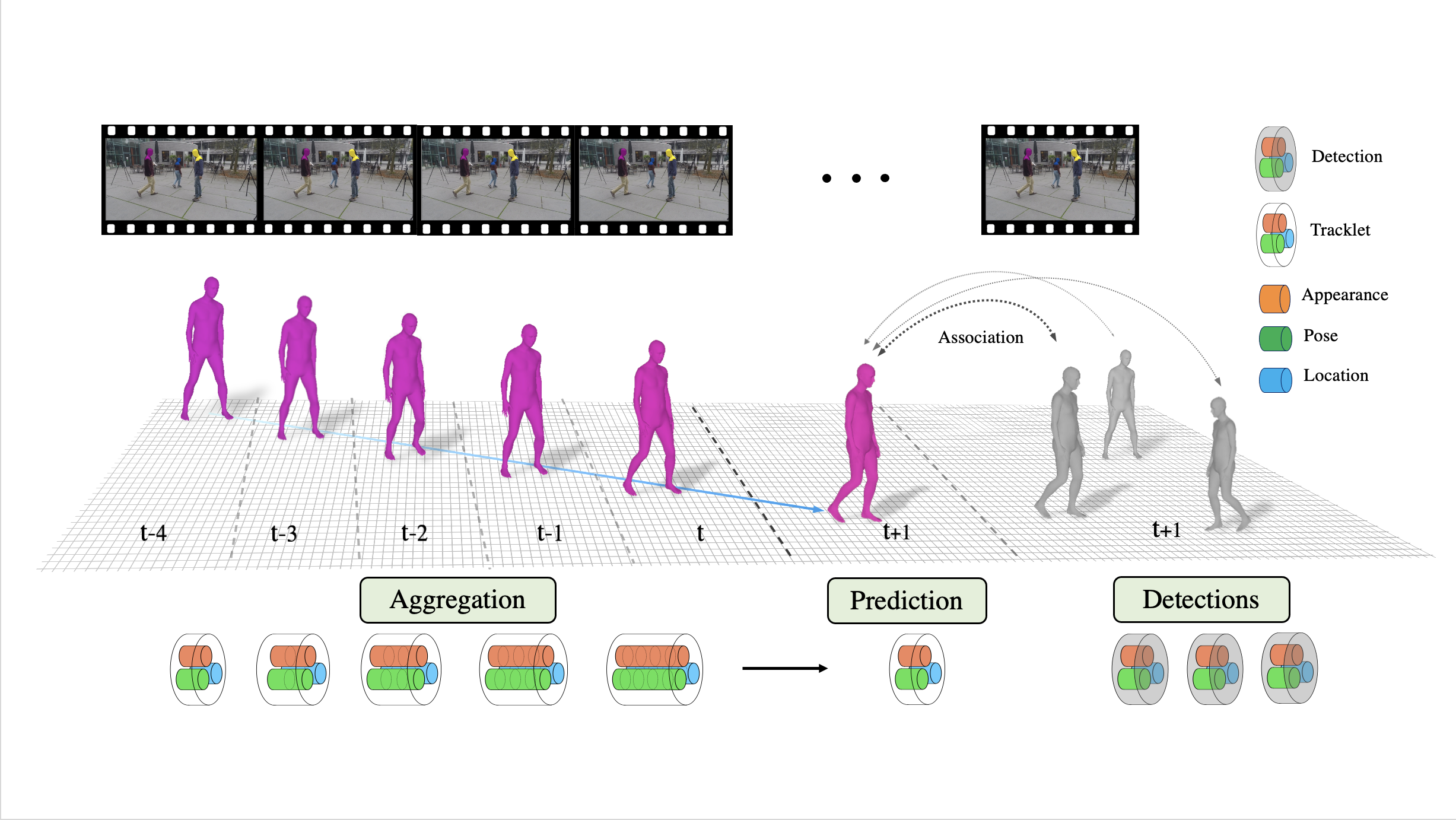 |
Jathushan Rajasegaran, Georgios Pavlakos, Angjoo Kanazawa, Jitendra Malik Computer Vision and Pattern Recognition (CVPR) , 2022 (Oral Presentation) (Best paper finalist - Top 0.4%) paper/ arxiv/ project page/ video/ results/ poster/ code Performing monocular tracking of people by predicting their appearance, pose and location and in 3D. |
 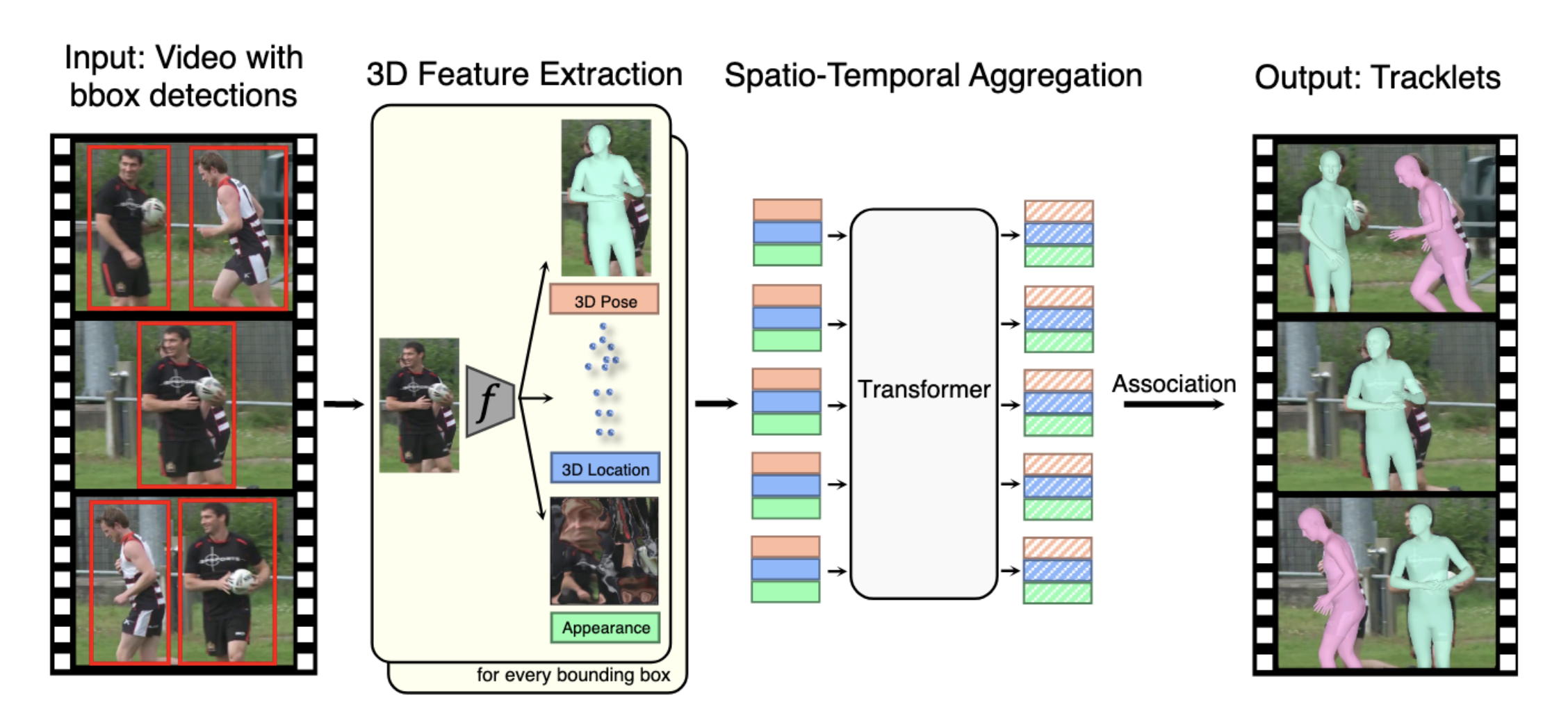 |
Jathushan Rajasegaran, Georgios Pavlakos, Angjoo Kanazawa, Jitendra Malik Neural Information Processing Systems (NeurIPS), 2021 paper/ arxiv/ project page/ video/ code/ poster Performing monocular tracking of people by lifting them to 3D and then using 3D representations of their appearance, pose and location. |
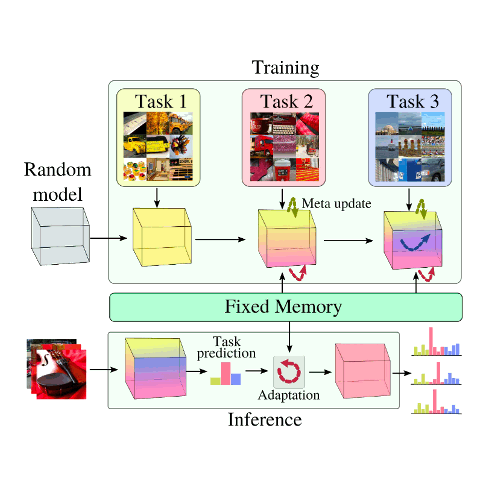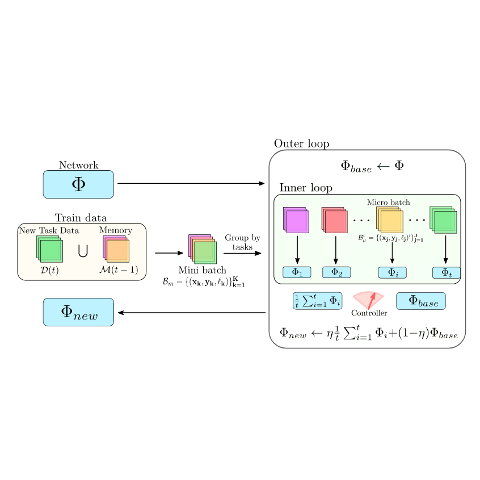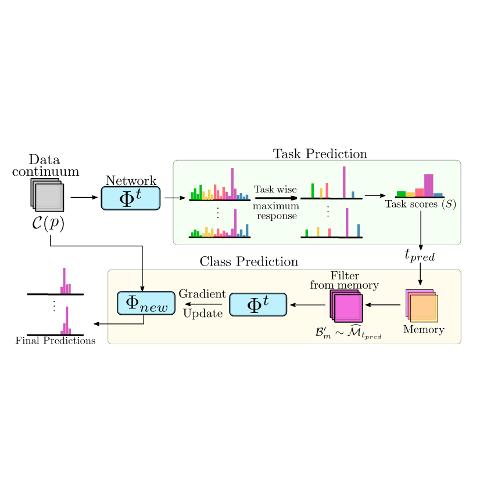 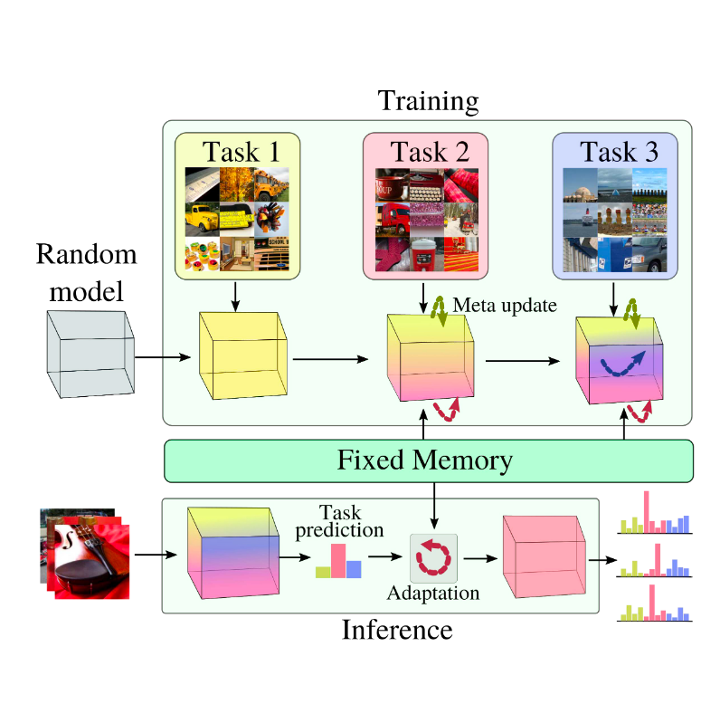 |
Jathushan Rajasegaran, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan Computer Vision and Pattern Recognition (CVPR) , 2020 paper/ arxiv/ slides/ video/ code By learning generic representations from past tasks, we can easily adapt to new tasks as well as remember old tasks. |
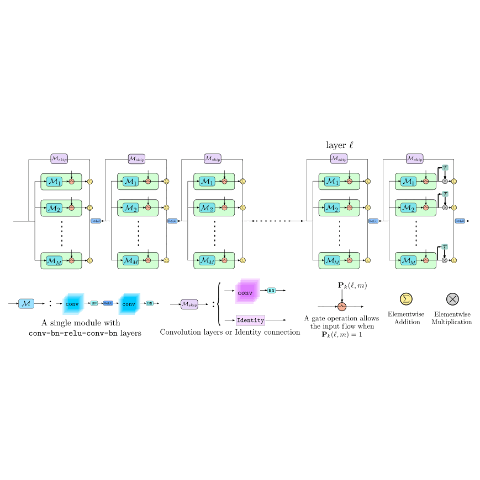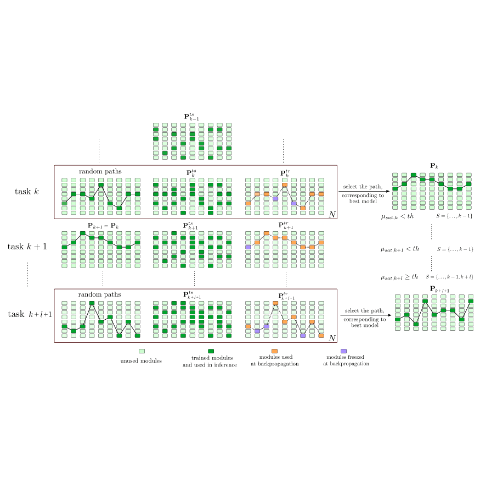 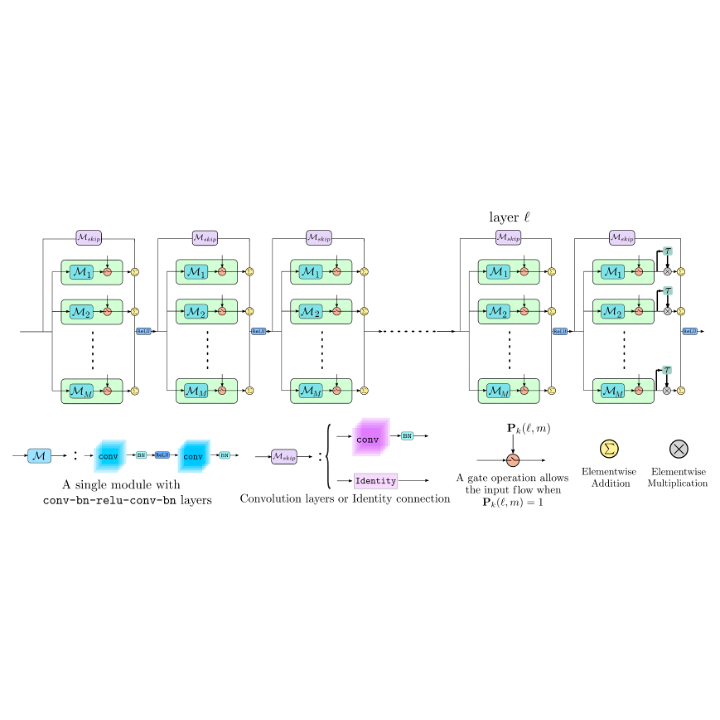 |
Jathushan Rajasegaran, Munawar Hayat, Salman Khan, Fahad Shahbaz Khan, Ling Shao Neural Information Processing Systems (NeurIPS), 2019 paper/ arxiv/ poster/ code We increase the width of a ResNet like model by adding extra skip connections when new tasks are introduced. |
  |
Jathushan Rajasegaran, Vinoj Jayasundara, Sandaru Jayasekara, Hirunima Jayasekara, Suranga Seneviratne, Ranga Rodrigo Computer Vision and Pattern Recognition (CVPR) , 2019 (Oral Presentation) paper/ poster/ video/ code Capsule Networks are cool, but they are shallow. We can increase the depth by 3D convolutions and skip connections. |
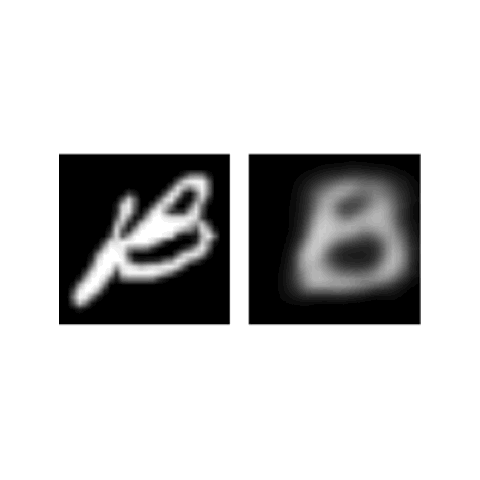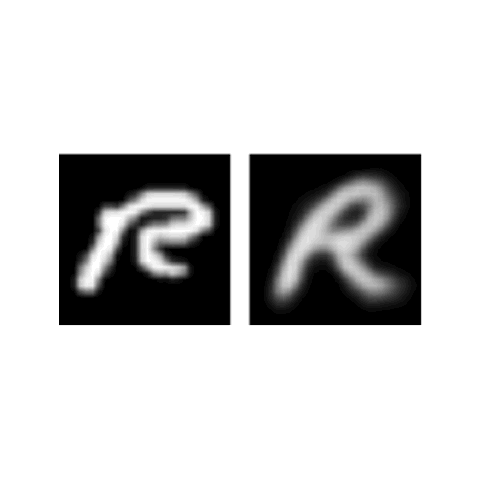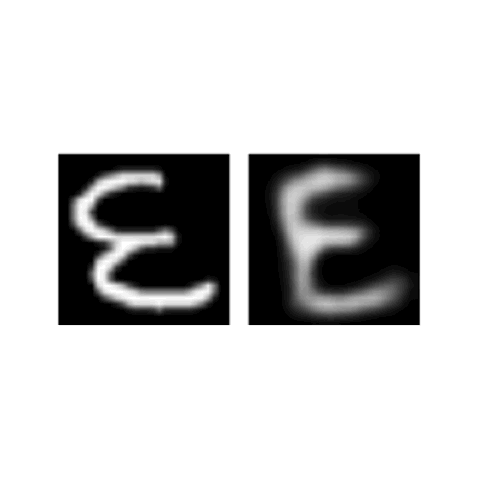 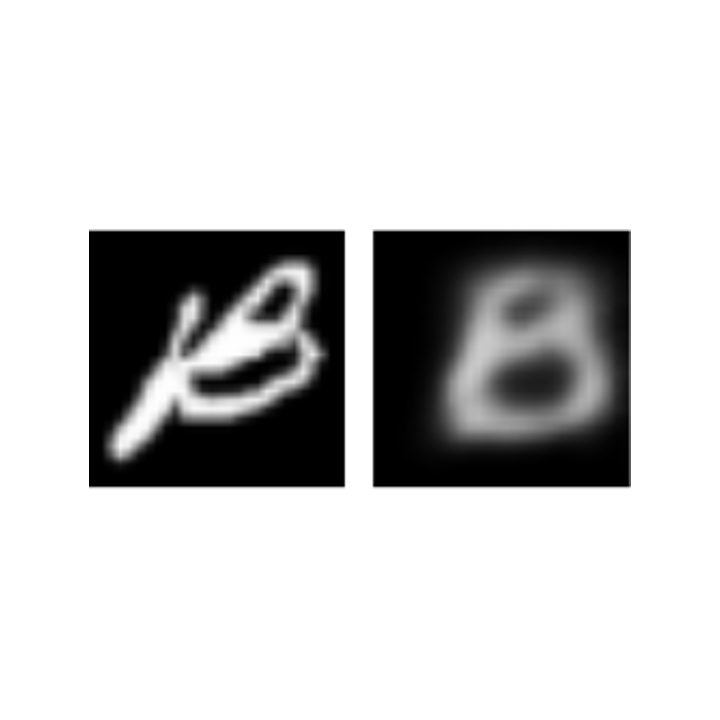 |
Vinoj Jayasundara, Sandaru Jayasekara, Hirunima Jayasekara, Jathushan Rajasegaran, Suranga Seneviratne, Ranga Rodrigo Winter Conference on Applications of Computer Vision (WACV) , 2019 paper/ arxiv/ poster/ code Capsule Networks can capture actual variations that are present in human hand writing, so we generate more data and retrain the capsule networks. |
  |
Jathushan Rajasegaran, Naveen Karunanayake, Ashanie Gunathillake, Suranga Seneviratne, Guillaume Jourjon International World Wide Web Conference (WWW), 2019 paper/ arxiv/ poster/ We use content and style representations detect counterfeit apps in playstore. |
{kind=link}
{kind=link}
|
Website source from Jon Barron here
|